

How Much Programming Do You Need for Data Science?

Let’s explore the coding skills needed for data scientists in 2026, the programming languages they will use, and how these languages help in data science projects.
Defining the Landscape of Data Science
Data science is a field that combines different areas to find useful information from large sets of data. Although the term is broad, it includes specific roles like data scientists, data engineers, and machine learning engineers.
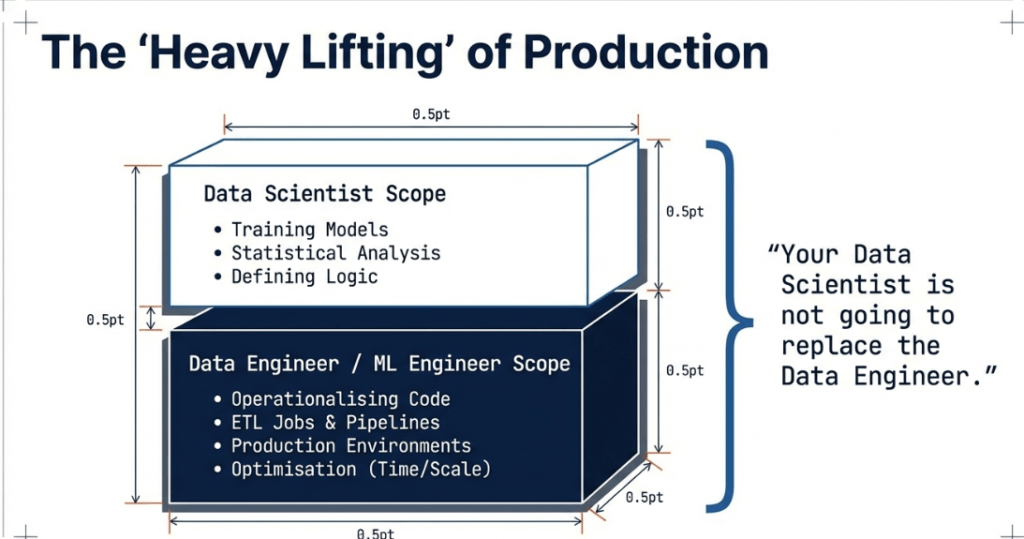
A data scientist mainly focuses on analysing data, looking for patterns, training models, and testing ideas for projects. It’s important to note that data scientists do write code, but how much they code can differ depending on their specific job and the team they work with.
In a good team, the data scientist collaborates with data engineers and machine learning engineers. The data engineer takes care of the tough tasks, like setting up systems and managing data processing jobs.
The machine learning engineer helps to put code into action, moving it from training to a live environment where it can create useful outputs like dashboards. This teamwork shows that the data scientist works with engineers, not instead of them, forming a strong partnership.
Why Data Science is a Critical Pillar of Innovation
Data science is valuable because it turns messy data into useful information. Companies use this information to make decisions based on facts instead of just guessing.
- Predictive Capabilities: By looking at past data, data science helps businesses predict what might happen in the future. This is important for managing stock, planning finances, and assessing risks.
- Efficiency and Automation: Data science can automate repetitive tasks, making work easier. For instance, machine learning can sort customer feedback or identify fraud quickly.
- Personalisation: Data science helps create personalised recommendations in streaming services and online shopping by analysing what people liked before.
- Informing Strategy: Dashboards and visual data help simplify complex information, giving executives clear insights into market trends and business performance.
The Programming Toolkit: High-Level Languages and Legacy Tools
A common point of discussion is the specific language a data scientist should master. while the field has evolved, several key tools and languages remain at the forefront.
Python and Scala: Python is a popular choice in data science because it’s easy to use. It helps professionals solve data issues without worrying about complicated details found in languages like Java.
Scala is also commonly used, especially with big data tools like Spark. The availability of Python and Scala APIs for Spark shows that the industry wants to make it easier for data analysts and scientists to work with data.
MATLAB and Excel are still commonly used tools, especially for individual projects or when starting to explore data. In team situations, data scientists often use MATLAB first, and then a data engineer helps move those methods to a larger, more efficient system.
The Move Towards Simpler Coding Most data scientists don’t need to write complex Java code. High-level tools like Pig and specific APIs for Spark were created to help data professionals run their code without worrying about the Java details.
This lets scientists concentrate on what they want to achieve (the algorithm and insights) instead of how to manage memory or system architecture.
Evolution of Tools The field is always changing. Tools like TensorFlow have made it easier to build and use models, allowing for a smoother shift from local machines to distributed systems compared to the past, when switching from Excel to Mahout meant completely changing the process.
How to Learn Data Science
Learning data science requires a structured approach that balances theoretical knowledge with practical application.
Step 1: Foundational Mathematics and Statistics Before touching a keyboard, a solid grasp of linear algebra, calculus, and statistics is necessary. These are the building blocks of the algorithms that data scientists use every day.
Step 2: Mastering a High-Level Language. Focusing on a high-level language like Python is a strategic move. One should focus on libraries specifically designed for data, such as Pandas for data manipulation, NumPy for numerical computation, and Scikit-Learn for machine learning.
Step 3: Understanding Data Manipulation (SQL) SQL (Structured Query Language) is the industry standard for interacting with databases. A data scientist must be able to query data independently to begin the analysis process.
Step 4: Data Visualization The ability to communicate findings is just as important as the analysis itself. Learning tools like Tableau, Power BI, or Python libraries like Matplotlib and Seaborn is vital for creating the dashboards.
Step 5: Machine Learning and Deep Learning Once the foundations are set, one should progress to understanding supervised and unsupervised learning. Exploring frameworks like TensorFlow, which the source notes has improved the transition to distributed algorithms, is essential for modern machine learning tasks.
Building for the Real World: How to Construct Projects
Building a project is the most effective way to demonstrate proficiency. A successful project should follow a lifecycle, moving from raw data to a production-ready state.
1. Problem Definition Every project should start with a clear question. Instead of just “analysing data”, the goal should be “predicting customer churn” or “optimising delivery routes”.
2. Data Collection and Cleaning One must gather data from various sources, which may involve the ETL jobs described in the source material. This phase is often the most time-consuming, as it involves handling missing values, removing duplicates, and ensuring the data is in a usable format.
3. Exploratory Data Analysis (EDA) This is where one uses tools like Excel or Python to find initial trends and outliers. Visualising the data at this stage helps in understanding the relationships between different variables.
4. Model Training and Testing In this phase, the data scientist selects an algorithm and trains it on a portion of the data. The model is then tested on a separate “holdout” set to ensure it can generalise to new, unseen information.
5. Operationalization and Deployment This is the stage where the scientist often collaborates with a machine learning engineer. The goal is to take the model out of a notebook environment and integrate it into an application or a dashboard where it can provide real-time value. This might involve using APIs or containerisation tools to ensure the code runs reliably in a production environment.
6. Documentation and Presentation A project is not complete until the results are documented. One should explain the methodology, the challenges faced, and the final impact of the project.
To work on real-time projects which make you industry-ready, enrol in White Scholar’s data scientist generative AI course in Hyderabad.
The Importance of the Team Context
Data science is a team effort. A data scientist doesn’t have to know everything about the process. You don’t need to be an expert in Java or systems administration to succeed.
Instead, focus on being a good coder in high-level languages and learn to work with engineers to turn ideas into reality. By working together and using the right tools for analysis and implementation, you can handle the challenges of data science and make a valuable contribution to the fast-changing world of big data.

Final Thoughts
Coding is a key part of data science, though its importance can vary. How much coding is needed depends on the organisation and the support from roles like data engineers and machine learning engineers.
Data scientists must be able to turn analytical ideas into working code. The rise of user-friendly languages like Python and Scala has made powerful tools like Spark more accessible, letting professionals concentrate on getting insights instead of dealing with complicated systems.
The field relies on teamwork, with scientists and engineers collaborating to take projects from training to production. Success is not about knowing every tool but using the right technology effectively as a team to tackle complex challenges.
Frequently Asked Questions
1. Do data scientists need to know how to code?
Yes, data scientists are expected to code, though the extent of this requirement depends on the specific role and the team support available. They use code to perform analysis, train models, and experiment with data.
2. Is deep knowledge of Java required for data science?
Typically, no; high-level languages and APIs like Python and Scala were created specifically so that data professionals could avoid the complexities of Java while still running powerful jobs in frameworks like Spark.
3. What is the role of a data engineer compared to a data scientist?
While a data scientist focuses on analysis and experimentation, a data engineer handles the “heavy lifting”, such as setting up environments, performing ETL jobs, and operationalising code for production.
4. Can legacy tools like Excel still be useful in data science?
Yes, tools like Excel and MATLAB are often used in solo environments or for initial data exploration before a project is transitioned to more scalable, distributed systems.
5. Why are high-level languages preferred over low-level languages in this field?
High-level languages like Python and Scala allow data analysts and scientists to execute complex code and run jobs without having to worry about the underlying infrastructure or components like those found in Java.