

Agentic AI Explained: How It Connects with Data Science

Learn what Agentic AI is, how it works, and why Agentic AI is becoming important in data science for smarter decisions and automation.
Agentic AI and its Architectural Core
The reactive character of conventional AI assistants and chatbots is fundamentally different from agentic AI. An agentic system is intended to be proactive, goal-driven, and self-sufficient, whereas a typical assistant waits for a human prompt to produce a response. It does more than just help; by observing its surroundings and working toward a specific goal with little assistance from humans, it acts, adapts, and learns.
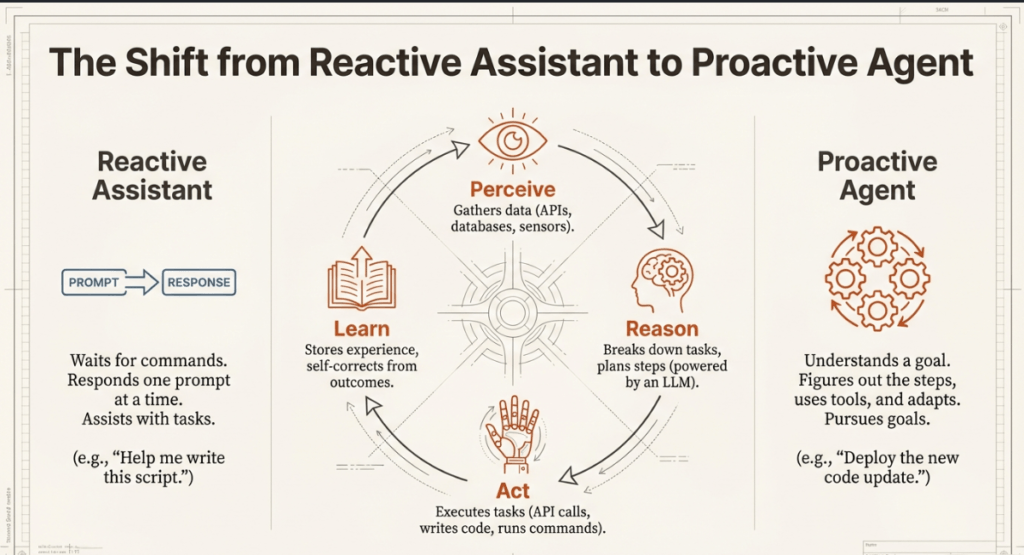
The AI’s ability to understand a complex goal, figure out the necessary steps, select the right tools, and adjust its plan in real time drives the transition from “research toys” to real-world products. An agentic system’s internal logic is structured in four steps: perceive, reason, act, and learn.
- Perception: The agent gathers signals from its surroundings using APIs, databases, user chats, sensors, and web searches. This enables the AI to “look around” and gather the necessary context for its task.
- Reasoning: Powered by foundation models such as GPT-4, Claude, or Mistral, the agent functions as a “brain,” breaking down the overall goal into a specific plan. It may use Retrieval Augmented Generation (RAG) to access external knowledge and ensure that its reasoning is based on real-time data.
- The agent puts the plan into action by carrying out real-world tasks like writing code, making API calls, sending emails, and running shell commands. If an action fails, the agent is programmed to self-correct.
- Learning: Each action and outcome is recorded in a feedback loop. Over time, the agent stores these experiences, making it more efficient in handling similar situations in the future.
A Large Language Model (LLM) for reasoning, a memory layer (short-term, such as conversation history, or long-term, using vector databases like Pinecone, Weaviate, or Faiss), tools or APIs for interacting with the world, and an orchestration framework are all required to build such a system.
Frameworks such as LangChain, OpenAI’s Agent SDK, CrewAI, and Microsoft’s AutoGen act as the “glue,” defining workflows and controlling how the LLM interacts with tools and memory.
Furthermore, the Model Context Protocol (MCP) creates a modular structure for these components to collaborate, ensuring that conversations and tool calls adhere to a clean, structured protocol rather than chaotic, uncoordinated prompts.
A code deployment agent can detect a code push, run tests, check for breaking changes, and notify the team via Slack, even rolling back the update if logs indicate a failure.
What is reflection?
Reflection is a design pattern used in agentic AI to create feedback loops and improve the accuracy of a model’s output. In a typical setup, an AI generates an answer token-by-token in a single pass, so it cannot naturally look back to correct its own errors.

Reflection alters this by allowing the system to go back, review, and tweak its work before delivering a final output. This procedure mimics how humans handle complex tasks.
For example, when writing a professional email, you most likely draft it first and then read it over to check for typos or tone; similarly, when writing code, you may run it, notice an error, and then adjust your logic based on that feedback. In an agentic system, reflection usually occurs in two ways:
- Self-Refinement: The AI is asked to evaluate its initial response and suggest improvements to its logic.
- External Feedback: The AI receives signals from the real world, such as database error messages or code execution results, and uses them to correct its path.
Reflection is strategically valuable because it allows for course corrections at any stage of a project. An agent can consider whether a user’s request is feasible, whether its own plan is logical, and whether the final solution meets the goal.
While this “second look” can improve accuracy by up to 20% to 30%, there are some drawbacks, such as higher costs and latency because the AI must perform multiple “thinking” steps rather than just one.
The Reflection Design Pattern and its Strategic Value
The reflection design pattern is a fundamental concept in agentic AI that seeks to create feedback loops in order to improve LLM accuracy. In standard AI setups, models generate answers token by token in a single pass, which means they cannot naturally review or correct their own errors during generation.
Reflection is similar to the human workflow; just as a person would draft an email and then review it for typos or consistency, reflection allows an AI to go back and review and tweak its output. It is essentially the process by which an AI evaluates its own logic or uses external signals to verify its performance.
Reflection is strategically important because it can be used at various critical stages of an agentic workflow.
- First, it can be used to perform feasibility checks, in which the LLM determines whether a user’s request is even possible given the available tools.
- Second, it aids in planning by allowing the model to double-check whether a proposed set of steps is logical and likely to achieve the desired outcome.
- Third, during execution, the agent can reflect after each tool call to determine whether the plan is still on track or needs to be adjusted.
- Finally, once the task is completed, the agent conducts a final review to ensure that the completed work addresses the original issue.
While reflection significantly improves reliability, there are significant latency and cost trade-offs. Because reflection necessitates multiple additional calls to the LLM and possibly other external systems, the user must wait longer for a result and consumes more tokens.
As a result, when deploying these systems in a business setting, developers must determine whether the quality improvements justify the additional cost and delays. Despite these costs, reflection remains at the heart of agentic flows because it provides an LLM with the necessary “conscience” to keep its progress on track with the end goal.
Methodologies and Frameworks of Reflection
There are several specific methods for implementing reflection, each backed up by extensive research. These frameworks transform reflection from a theoretical concept to a practical engineering pattern.
- Self-Refine (Iterative Refinement): Madaan et al. (2023) found that asking a model to provide self-feedback and then refining its response improved performance by about 20% across a variety of tasks, including mathematical reasoning and dialogue generation.
- Reflection (Verbal Reinforced Learning): Shinn et al. (2023) proposed this method for agents to learn from their mistakes through linguistic feedback. This method achieved 91% accuracy on the HumanEval coding benchmark, outperforming a standard GPT-4’s 80%. It is especially useful for complex tasks such as HotPotQA, which require reasoning across multiple documents.
- Gou et al. (2024) investigated the CRITIC (Tool-Interactive Critiquing) methodology, which focuses on external feedback. It allows LLMs to use external tools (such as search engines or code executors) to validate their own results. This approach has improved math problem solving and free-form question answering accuracy by 10-30%.
- The most well-known reflection framework is ReAct (Reasoning and Acting), which originated with Yao et al. (2022). It combines reasoning (explicit thought traces) with action.
In this scenario, the agent’s reasoning drives its actions, and the results of those actions generate new observations that inform future reasoning. ReAct is now a standard feature of major libraries like DSPy, LangGraph, and Hugging Face’s smol agents.
Using these frameworks, developers can transition from simple one-shot prompting to multi-turn reasoning systems capable of self-correction and higher-order logic.
Practical Implementation (The Text-to-SQL Case Study)
To demonstrate the importance of reflection, the authors provide a detailed case study involving a Text-to-SQL agent and a ClickHouse flight delay dataset.

The goal was to turn a user’s natural language question into a valid SQL query. The experiment consisted of three distinct stages to measure accuracy improvements:
- Direct Generation (Baseline): The LLM was given a system prompt containing the database schema and instructed to generate SQL directly. This approach had a 70% accuracy rate. While functional, it frequently failed to specify the appropriate output format or provided logic, resulting in SQL execution errors.
- Simple Reflection (Self-Critique): At this stage, the model was asked to evaluate its own generated SQL and suggest improvements. Surprisingly, this did not significantly improve quality, as the accuracy rate remained at 70%.
While the LLM fixed some minor formatting issues, it frequently overcomplicated the queries by introducing unnecessary logic (such as sampling) that the database did not support, resulting in new execution errors.
- Reflection with External Feedback: In this final stage, the LLM received external signals such as the actual output from the database (whether it was data or an error message) as well as a format check.
By determining why a query failed (for example, a “SAMPLING_NOT_SUPPORTED” error), the model can make informed corrections. This resulted in a significant increase to 85% accuracy, representing a 15% improvement over the baseline.
To confirm these findings, an LLM Judge (using a chain-of-thought approach) compared the agent’s output to a “golden set” of reference answers. The judge determined whether the queries had equivalent data, even if the formatting differed.
For example, when asked for “time airplanes spent in the air,” one query may include ground delays while another excludes them; the judge could use these nuances to determine whether the agent’s logic was correct. This practical example demonstrates that, while “self-reflection” can be beneficial, reflecting on external feedback is the most effective way to improve an agent’s performance.
Reflection with external feedback boosts text-to-SQL accuracy by replacing guesswork with grounded, objective signals that enable the model to self-correct based on real-world results.
In a typical “direct generation” approach, the LLM generates a query in one pass without being able to verify its functionality; reflection with external feedback introduces a loop that tests the system’s performance against a live environment.
This improvement occurs through a number of specific mechanisms:
- Correction of Execution Errors: By sharing the actual database output, including error messages, the LLM can determine why a query failed. For example, if a database returns a specific error, such as “SAMPLING_NOT_SUPPORTED,” the agent can immediately remove the faulty logic rather than assuming what went wrong.
- Verification of Formatting Requirements: External feedback can include static checks to ensure that the SQL follows specific architectural rules.
- Refinement of Business Logic: When a model sees the data returned by a query, it can consider whether it logically answers the user’s question. This allows it to revise nuances such as selecting “total elapsed time” or “time in the air” for speed calculations.
- Avoiding Overcomplication: Simple reflection (in which the LLM simply critiques itself without using external data) frequently fails to improve accuracy and can even result in the model misinterpreting a correct query as incorrect. External feedback serves as a reality check, keeping the model from including unnecessary or unsupported features.
Quantifiable impact. In a practical case study using a flight delay dataset, the accuracy of the text-to-SQL system followed a clear path:
- Direct generation achieved 70% accuracy.
- Simple Reflection: The model remained at 70% accuracy because it lacked new information to correct its errors.
- Reflection with External Feedback: Improved to 85% accuracy, a significant 15 percentage point increase.
Research frameworks such as CRITIC back up these findings, demonstrating that using external tools to verify and correct outputs can improve accuracy by 10-30% across a variety of complex tasks.
While multiple LLM calls increase latency and token costs, they are required for the development of reliable agentic systems.
How Agentic AI Combines Generative Intelligence and Data Science
Agentic AI represents the next stage of artificial intelligence, progressing from simple conversational interfaces to systems capable of pursuing goals autonomously. Its relationship to generative AI (GenAI) and data science is fundamental; it employs GenAI’s reasoning power to perform complex analytical tasks that have traditionally been handled by data scientists.
1. Agentic AI and Generative AI: The Core Reasoning Engine
Generative AI, specifically Large Language Models (LLMs), functions as the “brain” or central reasoning unit in any agentic system. GenAI in its most basic form is reactive, responding to one prompt at a time. Agentic AI employs GenAI to orchestrate complex workflows.
- Agentic AI uses the generative capabilities of models such as GPT-4 or Claude to decompose a high-level goal into smaller, more actionable steps. It generates a strategy, not just text.
- Contextual Reasoning: Using techniques such as Retrieval Augmented Generation (RAG), agents can access external knowledge bases to ensure their reasoning is based on real-time, accurate data, preventing the “hallucinations” that are common with standalone GenAI.
- Orchestration Frameworks: Tools such as LangChain, CrewAI, and Microsoft’s AutoGen serve as the glue, connecting the LLM’s generative power to memory layers and external tools, allowing the AI to “stay on track” through multiple turns of a conversation.
2. Agentic AI and Data Science: Automated Expertise
In the field of data science, agentic AI functions as a “digital analyst,” capable of carrying out technical tasks that previously required human intervention.
- Text-to-SQL and Data Retrieval: One major intersection is the conversion of natural language into database queries. Agents can understand a user’s query, examine a database schema (such as a flight delay dataset), and generate the exact SQL code required to retrieve the answer.
- Agents interact with the world using data science tools such as SQL executors, Python environments, and vector databases (e.g., Pinecone or Weaviate). They can execute code, check for errors, and analyze results independently.
- Objective Quality Measurement: Agentic systems frequently use LLM judges to assess data quality. These judges use chain-of-thought reasoning to compare agent-generated data to reference datasets and determine whether the logic is correct, essentially automating the peer-review process in data analysis.
3. The Feedback Loop: Where the Disciplines Meet.
The true power of agentic AI lies in the feedback loop, which combines the iterative nature of data science with GenAI’s creative flexibility.
- Perception and Data Gathering: The agent perceives its surroundings by gathering information from APIs and databases, which is an essential data science activity.
- Action and Execution: The agent runs SQL queries and shell commands.
- Reflection (The Design Pattern): The agent evaluates its own work. In a data context, if a SQL query fails, the agent does not simply exit; instead, it examines the database error message (external feedback), determines why it failed, and generates a modified query. This iterative refinement has been shown to increase accuracy in data tasks by 20-30%.
- Continuous Learning: Each outcome is saved in a memory layer, allowing the system to learn which analytical paths work best for specific types of data questions, effectively “training” itself over time without requiring manual retraining of the underlying model.
Students interested in agentic AI should begin with data science. This foundation explains how algorithms, like those used by Instagram and YouTube, work with data. WhiteScholars provides a six-month intensive (180-hour) course covering SQL, Python, Power BI, and Tableau.
Training highlights:
- Expert Mentorship: Learn from data scientists with over ten years of experience at top companies.
- Practical Experience: Build a strong portfolio by completing eight domain-specific projects and weekly assignments.
- Career Support: Get guaranteed interview opportunities and virtual internships with Accenture and PWC.
- Certifications include official recognition from Microsoft and NASSCOM.
WhiteScholars’ mission is to provide personalized, impactful training that helps people become job-ready professionals. This structured curriculum ensures that your skills are current and immediately applicable in an evolving AI landscape.
Final thought
Generative AI provides logic, data science provides the environment and tools, and agentic AI provides autonomous driving. This evolution indicates that we are transitioning from tools that simply answer questions to systems that solve problems by thinking, acting, and correcting themselves in real time.
Agentic AI with reflection symbolizes the evolution of artificial intelligence. While the additional steps of reasoning and critiquing cost money and time, they provide a level of dependability and autonomy that was previously unavailable.
As these systems become more modular through protocols such as MCP, the line between “magic” and engineering blurs, ushering in a future in which AI does more than just talk to us; it also solves problems for us.
Frequently Asked Questions
1. What distinguishes agentic AI from traditional AI assistants?
Traditional assistants are reactive, waiting for human prompts to provide a single response, whereas agentic AI is proactive, assuming a goal and pursuing it. It perceives its surroundings, thinks through complex tasks, and uses tools independently to adapt and achieve goals with little human intervention. Essentially, it acts, adapts, and learns through its own operational cycles, rather than simply providing assistance.
2. Describe the four stages of the agentic AI operational loop.
The cycle begins with perception, in which the agent collects data from various sources such as APIs, databases, and web searches. This is followed by reasoning, in which an LLM plans the steps and chooses tools, and finally action, in which it performs tasks such as writing code or making API calls. Finally, the agent learns, storing the experience and constantly refining itself for similar future situations.
3. How does the “reflection” design pattern increase AI accuracy?
Reflection creates feedback loops, allowing an LLM to review and improve its work rather than producing an answer in a single, uncorrected pass. The system can identify errors and improve its output by asking the model to critique its own logic or providing external signals. According to research, this pattern can improve performance by 20% to 30% on a variety of reasoning and coding tasks.
4. What is the difference between simple self-reflection and reflection with external feedback?
Simple reflection involves the LLM critiquing its own output based on internal logic, which can sometimes lead to over-complication without real improvement. External feedback provides the model with objective signals, such as database error messages or execution results, to ground its corrections in reality. In a text-to-SQL study, adding external feedback boosted accuracy from 70% to 85%.
5. What are the primary trade-offs when implementing reflection in AI systems?
While reflection significantly boosts reliability and accuracy, it comes at the cost of increased latency and higher operational expenses. Because the process requires multiple additional calls to the LLM and external systems, the user must wait longer for a result. Businesses must evaluate whether the quality improvements provided by these loops justify the additional token costs and delays.