

A data scientist’s daily routine: Assumptions versus reality

Let’s take a look at a data scientist’s daily routine, what they do, the types of projects they work on, and how their role is implemented in 2026.
The Multi-Faceted Role of a Data Scientist
In a modern tech environment, particularly within growth marketing or product-focused companies, a data scientist does not work in isolation but is deeply integrated into the product engineering team.
This positioning means they are part of the arm of the business that builds and maintains the actual tech platform users interact with. Their primary function is a dual one: developing and maintaining new features on the platform while simultaneously collaborating with stakeholders to determine how data can be leveraged to add business value.
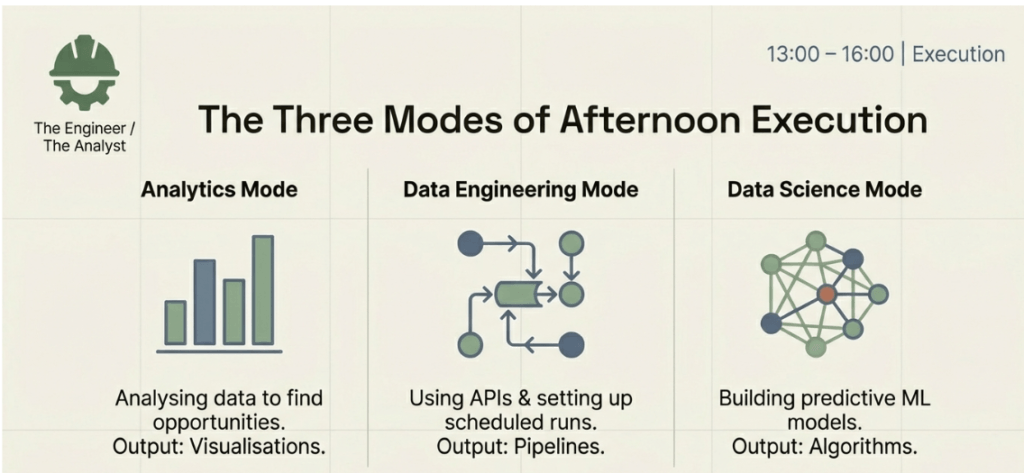
The role is rarely static and often involves a blend of three distinct disciplines:
Business and Data Analytics: This involves the deep analysis of existing data sets to uncover opportunities for stakeholders and the creation of meaningful visualisations to communicate these findings.
Data Engineering: A significant portion of the work involves building the infrastructure for data. This includes using APIs to pull data from third-party sources and setting up automated schedules to ensure data flows correctly.
Core Data Science: This is the more traditional “science” aspect, focusing on building predictive machine learning models to solve complex problems.
A Day in the Life: Routine and Tasks
A data scientist must balance personal technical work with team collaboration.
Morning: Planning and Deep Work
The day typically begins around 8:30 AM with a simple routine to prepare for the workday. In a remote setting, communication starts on platforms like Slack, where the team provides text updates outlining the day’s goals. A successful data scientist often translates these team goals into a detailed personal to-do list to track progress.
A critical component of the morning is “Deep Work”. This is at least one hour of uninterrupted time dedicated to high-level research and complex problem-solving. For example, using this time to research machine learning techniques specifically designed to summarise and categorise large volumes of text.
The Meeting Landscape
Communication is a constant necessity in data science. These meetings are categorised into four main types:

- Team Stand-ups: Short, 15-minute sessions held every second day to discuss current tasks, blockers, and timelines.
- Stakeholder Meetings: Fortnightly sessions where data scientists share their initiatives and insights with leaders across the organisation.
- Management One-on-Ones: Weekly or fortnightly check-ins with managers or direct reports to prioritise immediate tasks, provide feedback, and discuss career development.
- Company All-Hands: Monthly updates where leaders share broader organisational news.
Afternoon: Technical Execution and Projects
When the afternoon is free of meetings, it is dedicated to uninterrupted technical tasks. This is where the core “building” happens. A data scientist might spend several months on a single project, such as a text mining project to analyse free-text data.
Specific tasks during this time include:
- Data Extraction: Using SQL daily to manipulate and extract data from company databases.
- Data Preparation: Calling APIs to handle raw external data and preparing it for model ingestion.
- Modelling: Training and building machine learning models using Python within Jupyter Notebooks.
- Standardisation: Developing “one-size-fits-all” functions, such as a text-cleaning function, that can be applied across different client data sets.
- Documentation: Before taking time off or handing over a feature, a data scientist must write handover documents and add extensive comments to their code so that software engineers can implement the features correctly.
Reality vs. General Perception
Several ways the professional reality of data science differs from common misconceptions:
- The “Many Hats” Reality: While people often think data scientists only do “math”, in smaller organizations, they must be versatile. The product/engineering team might be small (e.g., five people), requiring the data scientist to act as a data engineer, analyst, and researcher all at once.
- Research vs. Business: There is a common perception that data science is either purely business-facing or purely academic. In reality, it is often both. A role can shift from being “business-facing” to being a research-heavy machine learning specialist depending on the project’s technical demands.
- The Myth of Perfection: Many beginners struggle with the desire for a perfect model. However, the industry reality relies on the 80/20 rule. It is more important to have a functional, “good enough” model that can be delivered now than to spend months chasing minor improvements that delay the project.

- The Learning Curve: The job is not just about applying what you already know; it involves a “steep learning curve” where you frequently realise how much you still have to learn, especially when dealing with complex projects like text mining.
Advice for Aspiring Students
To succeed in this field, students should focus on the following practical areas:
- Prioritise the Right Languages: Universities often focus on Matlab or R in mathematics or science degrees. While the logic is transferable, the industry standard is SQL and Python. Students should ensure they are proficient in these before entering the job market.
- Embrace AI Tools: Modern tools like ChatGPT are a “godsend” for solving specific coding hurdles, such as finalising complex functions or debugging text-cleaning scripts.
- Focus on Documentation and Communication: Technical skill is only half the battle. You must be able to script voiceovers for presentations, write clear handover documents, and comment on code so that non-data scientists (like software engineers) can understand your work.
- Develop Deep Work Habits: Success requires the ability to time-block efficiently and commit to “deep work” sessions for research.
- Continuous Improvement: Data science is research-heavy. You should be prepared for late nights of research and a constant cycle of learning new techniques as technology evolves.
How does structured training help?
Working as data scientists, learners get real-time data which may not align with the topics or knowledge that they have gained by watching some random YouTube videos. Most of the time goes into understanding these data sets, which delays the project.
In order to stay ahead of this rapidly evolving field, along with continuous learning, there should also be projects. While coming to the projects, anyone can work on basic projects and showcase their skills, but WhiteScholars’s data science course not only makes their students learn from real-time projects but also connects the course with generative AI.
If you are looking to start your career as a data analyst , WhiteScholars Academy offers a Data Analyst course with 7-plus real-time projects and certification.
The training mode is hybrid and also integrated with communication tests, along with placement opportunities to improve the soft skills of the learners, and several mock interviews are conducted to secure higher chances of landing the job.
Final Thoughts
A vital lesson for those entering the field is to embrace the 80/20 rule, focusing on delivering a functional model rather than chasing unattainable perfection. Technical success relies on a strong foundation in SQL and Python, tools that are often more prevalent in the industry than academic languages like Matlab.
Beyond coding, the ability to produce clear handover documentation and detailed code comments is essential for seamless collaboration within a product engineering team. Ultimately, the career offers a rewarding but “steep learning curve”, providing a unique balance of technical research and personal flexibility for those who can manage their time and prioritize tasks efficiently.
5 Most Asked Questions
What does a data scientist’s role involve on a daily basis?
It involves a split between developing new features on a tech platform and collaborating with stakeholders to identify how data can add business value. Typical tasks include SQL data extraction, building models in Python, and researching machine learning techniques.
What types of meetings do data scientists typically attend?
They participate in 15-minute team stand-ups to discuss blockers, fortnightly stakeholder meetings to share insights, and regular one-on-ones with managers for career development and task prioritisation.
What technical tools are considered essential for the job?
The industry standard heavily prioritises SQL for database manipulation and Python (using Jupyter Notebooks) for building machine learning models. Additionally, APIs are used for data ingestion, and tools like ChatGPT can help solve specific coding hurdles.
How do you manage complex or long-term technical projects?
Success comes from dedicated “deep work” sessions for research and the persistence to navigate a “steep learning curve”. It is also crucial to provide thorough documentation and code comments to ensure fellow engineers can implement the features.
Is the work strictly limited to “data science” models?
No; in smaller teams, data scientists often act as data engineers and business analysts, creating visualisations and automated data pipelines alongside their modelling work. The role requires balancing being a research-heavy specialist with a business-facing analyst.